Assignment #3 - When Cats meet GANs
Adithya Praveen
I. Project Description
The goal of this project is to understand Generative Adversarial Networks (GANs) better by getting our hands dirty and implementing some popular GAN architectures like:
II. DCGAN
Method
Just like a typical GAN, the DCGAN architecture also has a generator and a discriminator. The main difference is DCGAN's use of convolutional layers combined with normalization and activation layers as shown in the diagrams below:
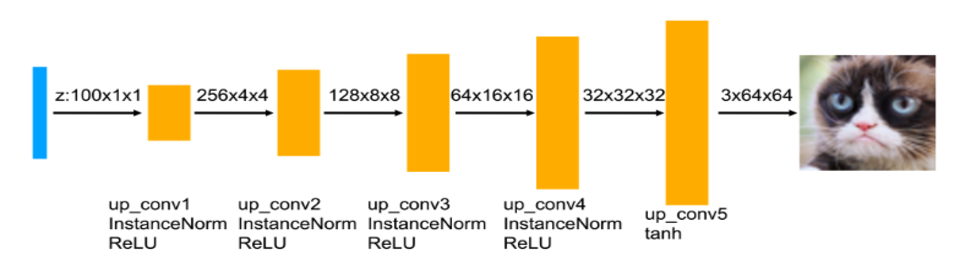
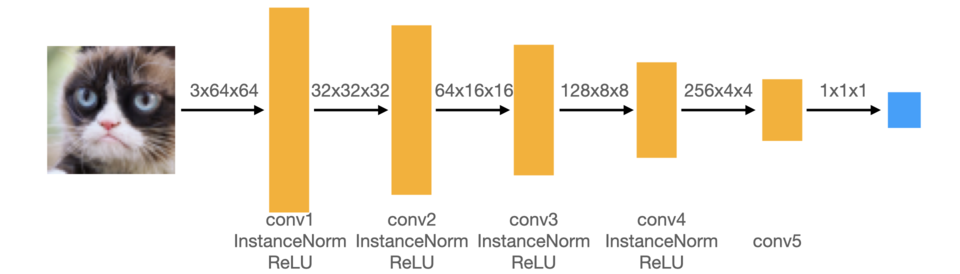
Note: Real images have a label of 1, and fake images have a label of 0.
As with GANs in general, we begin by sampling random noise which is fed into the generator - giving us our batch of "fake images". Both networks are now ready to "learn".
The discriminator has two missions: Classify all real images as real, and all fake images as fake. So the first term below (D’s ability to classify real images as real) is zero when D outputs 1 for real images. The second term (D’s ability to classify fake images as fake) follows similar logic. Mathematically, this can be expressed as follows:
$$J^{(D)} = \frac{1}{2m}\sum_{i=1}^{m}\left[\left(D(x^{(i)}) - 1\right)^2\right] + \frac{1}{2m}\sum_{i=1}^{m}\left[\left(D(G(x^{(i)}))\right)^2\right]$$
The generator's job is to fool the discriminator. Said differently, G wants D to always output 1 for the images it creates - that’s exactly when the G’s loss function maps to zero. This can be concisely expressed as: $$J^{(G)} = \frac{1}{m}\sum_{i=1}^{m}\left[\left(D(G(x^{(i)})) - 1)\right)^2\right]$$
The proof is in the padding [I'm sorry]
Here's the proof of the padding value p used in all (except the last layer) in DCGAN's discriminator. The exception is the last layer: Since we want a single output, padding doesn't really make sense in that context (therefore it was set to 0). In all other layers, we use a padding value of 1 as shown below:

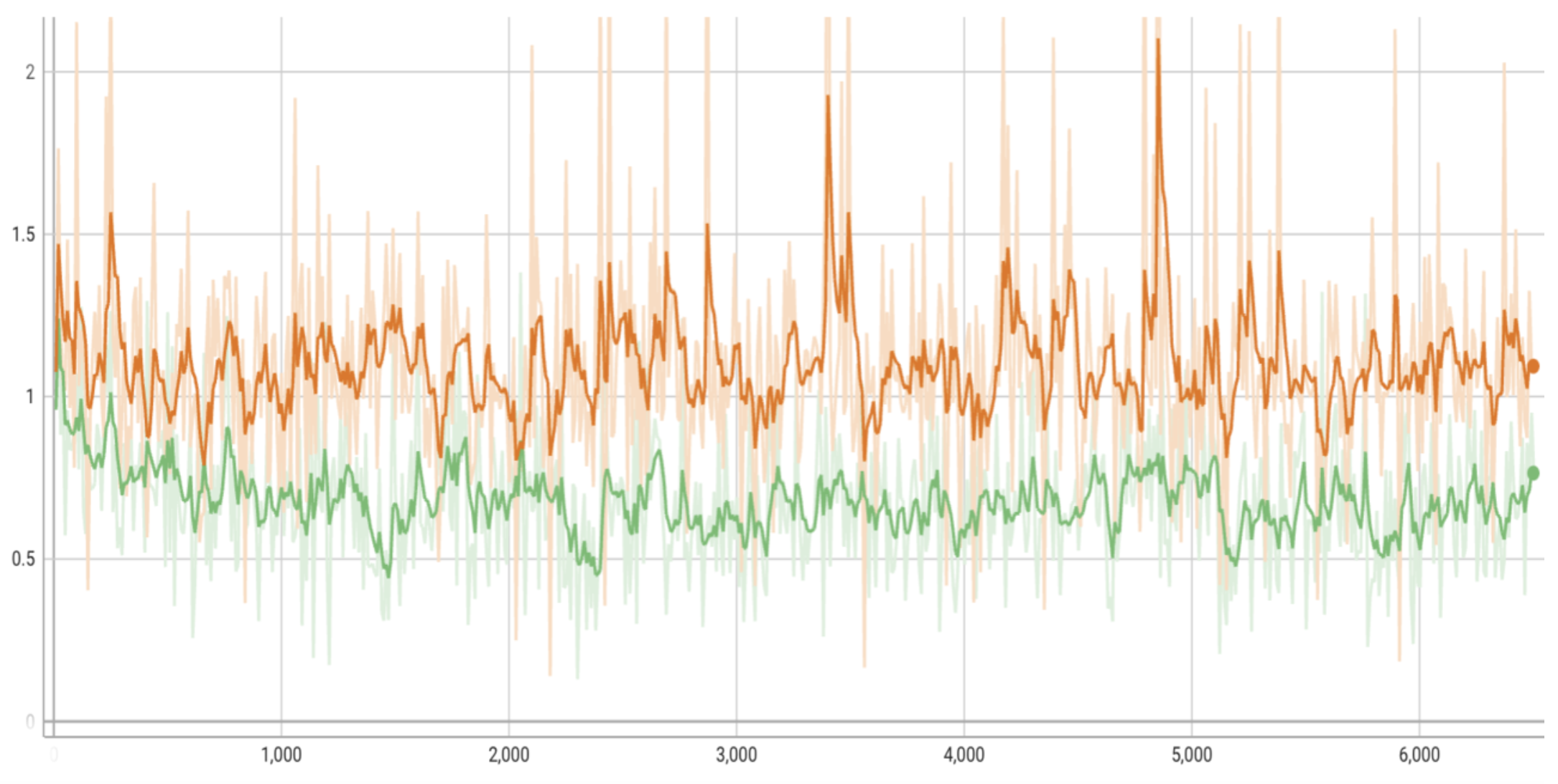
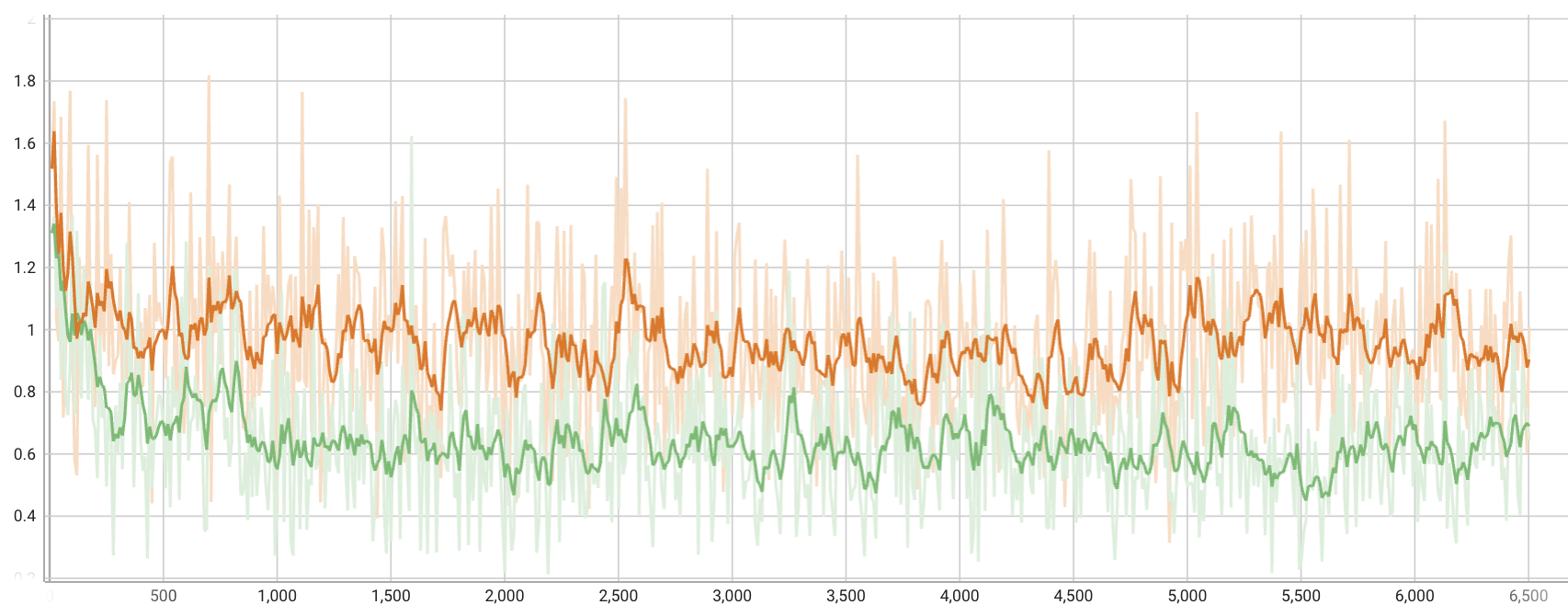
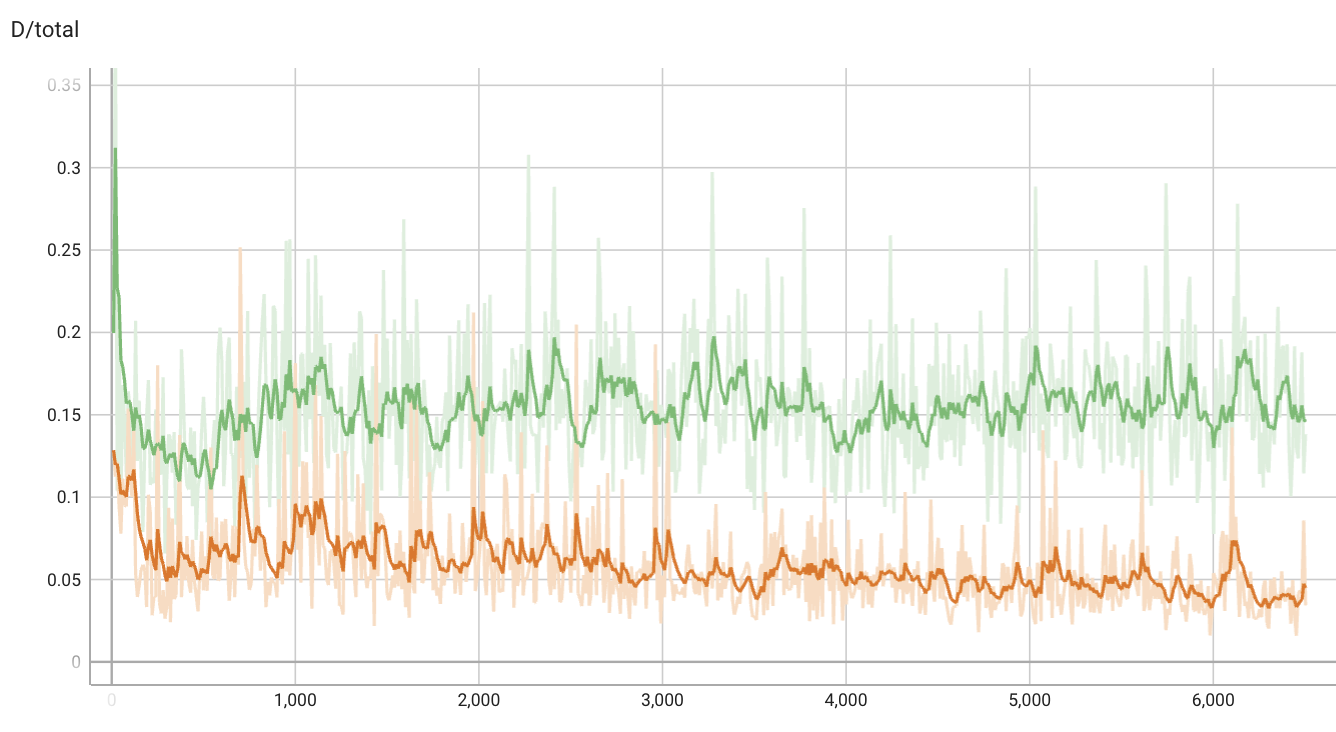
Loss Curves
A few notes on the loss curves:
--data_preprocess=basic [--use_diffaug]
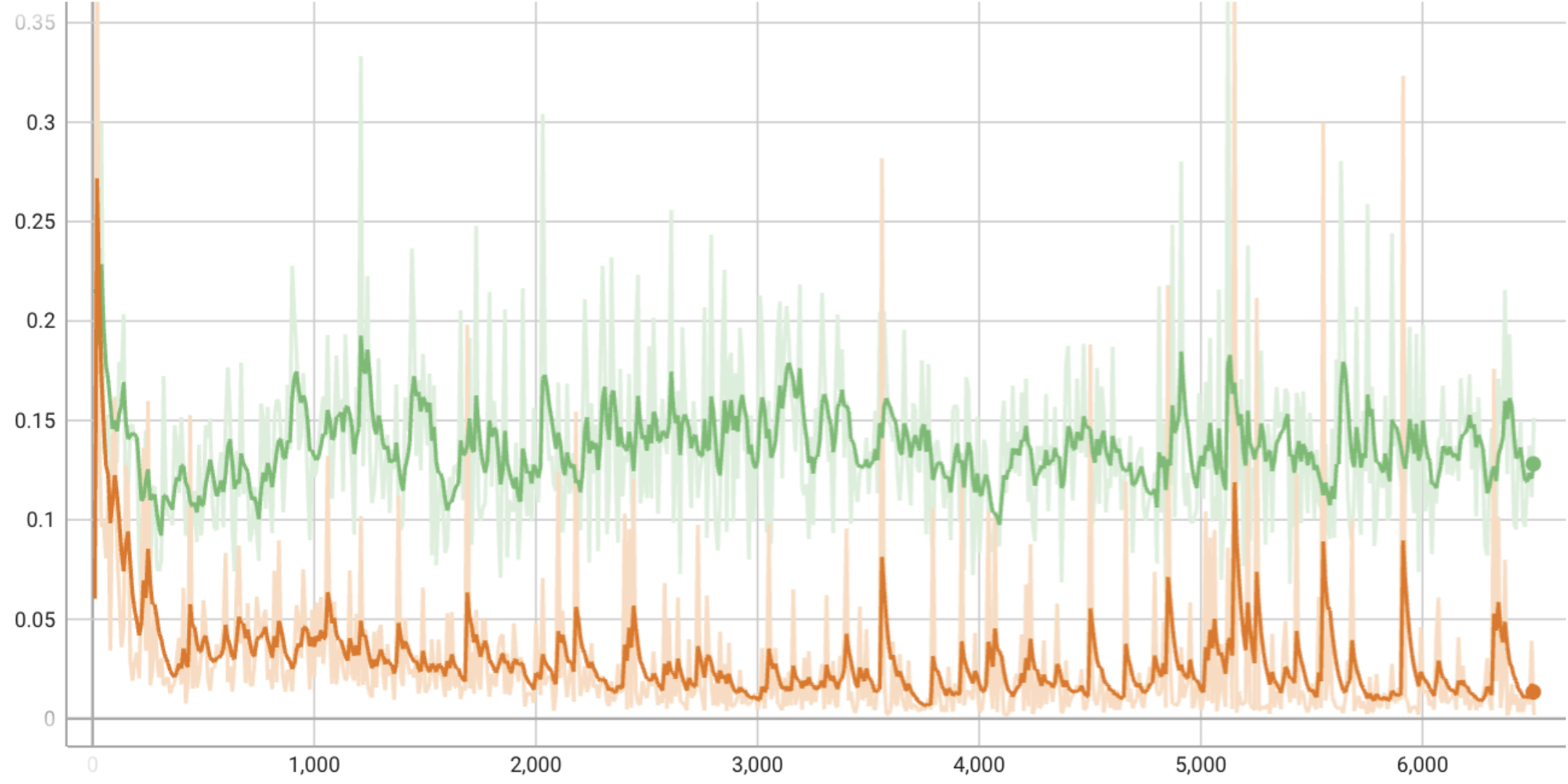
--data_preprocess=deluxe [--use_diffaug]
Generated Samples
Here, we show samples generated using deluxe data preprocessing without and with differentiable augmentation. In both cases, there is a clear improvement in quality going from iteration 200 to iteration 6400. Initially we have very blurred generations and towards the end of training, we see some cats that are very clearly grumpy.
It is also worth noting that most of the grumpy cats generated via DCGAN trained with differentiable augmentation, tend to have both eyes than the DCGAN trained without such augmentation. Simply put, training with differentiable augmentation tends to produce generations of relatively superior quality.
--data_preprocess=deluxe


--data_preprocess=deluxe --use_diffaug


III. CycleGAN
Method
In this section we deal with the task of image-to-image translation. The task is to convert images from a source domain (X) to look like images in a target domain (Y), while preserving the structural properties of X as much as possible. The CycleGAN architecture makes this possible in atleast two ways:
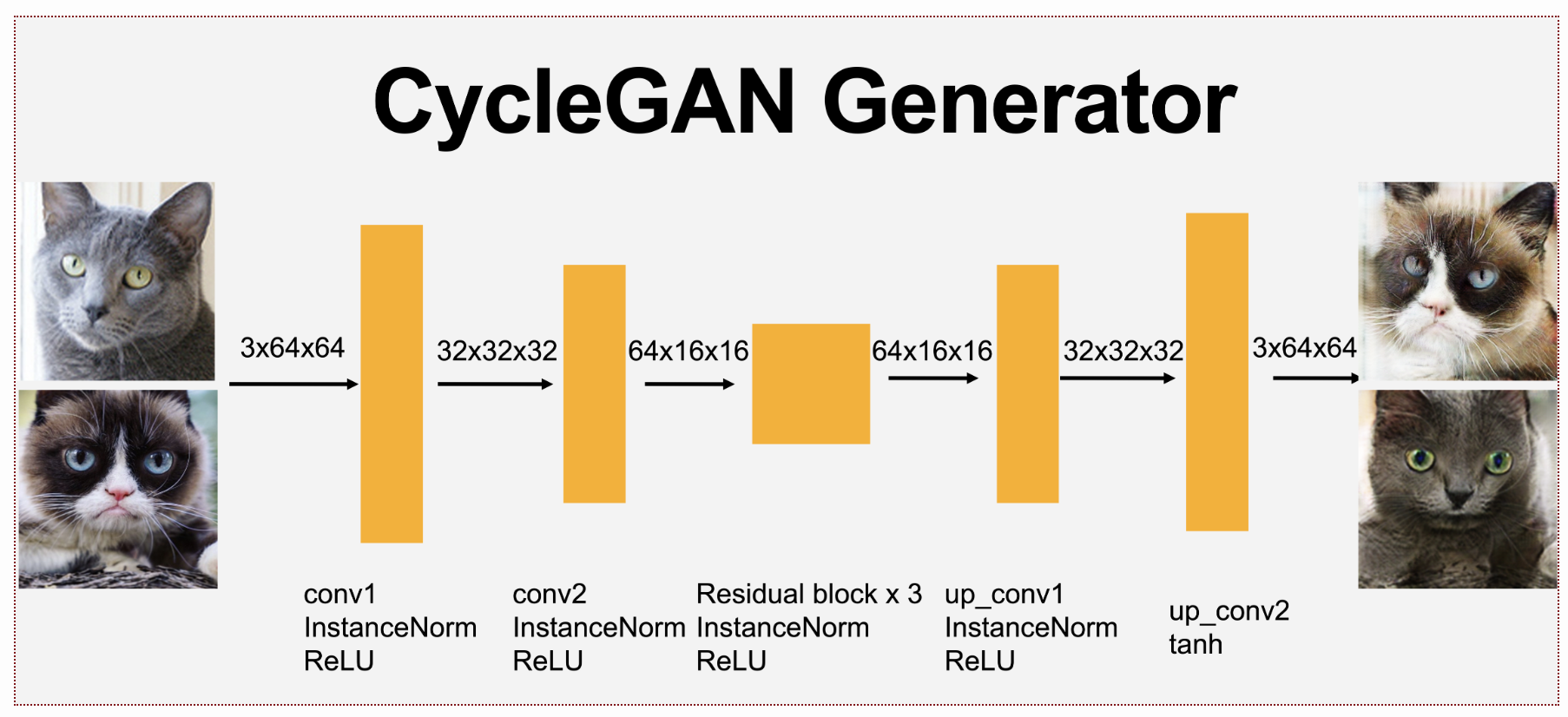
Clearly, the above loss suggests that we have two generators in CycleGAN - one that translates from X → Y, and another that translates from Y → X (both share the exact same architecture). Additionally the (patch) discriminator classifies patches instead of the entire image as being real or fake - to better model local shapes. We only include the architecture of the generator below, since the discriminator is essentially the DCGAN discriminator without the final layer.
Early Results
Here are some of the earlier results of our CycleGAN with patch discriminator on the first dataset of cats (Grumpy and Russian Blue). These are results after a 1000 iterations, and we have two sets of results without and with cycle consistency loss. Observations are stated in the Final Results: Cats section.
--disc patch --train_iters 1000


--disc patch --use_cycle_consistency_loss --train_iters 1000


Final Results: Cats
Cycle Consistency Comparison
As in the previous section, the second set of results use cycle consistency loss.
[Positive] We see that it's better in atleast two ways:
[Negative] Something that is not too great about using cycle consistency loss is the following:
--disc patch --train_iters 10000


--disc patch --use_cycle_consistency_loss --train_iters 10000


DC Discriminator Comparison
Here we compare the results of image to image translation when using DC discriminator instead of the patch discriminator used in the previous sections.
--disc dc --use_cycle_consistency_loss --train_iters 10000


Final Results: Fruits
Cycle Consistency Comparison
Following the structure of the cats dataset, we also analyze the results from the fruits dataset.
[Positive]: It is worth noting that the orange to apple translation has more nuance in the version with cycle consistency loss. Instead of simply converting to a red blob, with cycle consistency we see lighter yellowish shading along with red, making it look more like an apple. This is especially evident when the source orange has been sliced (see top-left image).
[Negative]: The version with cycle consistency loss however, converts all white-ish objects to black which throws off the aesthetic some times. The effect is probably related to the choice of p-norm being 1 in the cycle loss.
--disc patch --train_iters 10000


--disc patch --use_cycle_consistency_loss --train_iters 10000


DC Discriminator Comparison
Without a patch based discriminator, the image translations seem to be more grainy and blurred, and this is expected.
--disc dc --use_cycle_consistency_loss --train_iters 10000


IV. Bells and Whistles
Train Diffusion Model
I trained a diffusion model from this HuggingFace notebook that introduces us to their new "diffusers" library - "diffusers" makes it incredibly easy to play around with diffusion models on your own datasets. I specifically used the Denoising Diffusion Probabilistic model (DDPM) model pipeline.
I used 1000 timesteps for the denoising process, but I've included 10 equally spaced timesteps below - play with slider to see some 32x32 grumpy cats emerge out of random noise!










Pretrained Diffusion
Here are some anamorphic versions of grumpy and russian blue cats. I first optimized my prompt with the prompt optimizer promptist. I then generated samples using a pre-trained diffusion model from DreamBooth as shown below.


GAN Meme
And finally, here's what would happen if you let a GAN make a cat meme.
